Applied Data Science Capstone: Most Similar Neighborhood in Another City
1 Introduction
1.1 Background
São Paulo and Rio de Janeiro are the two largest cities in Brazil. Although relatively close (given the continental dimensions of the country), they have very different characteristics. One of the factors that contribute to the existence of these discrepancies is the obvious geographical distinctions that naturally shape social behavior and, indirectly, the urban structural configuration. The beaches of Rio de Janeiro, for example, give residents a natural option of entertainment and the nearest commercial places have characteristics aimed at this purpose. On the other hand, in São Paulo, entertainment options are directly dependent on experiences that can be provided as a business model.
From a social point of view, Rio de Janeiro inherits aristocratic characteristics, for having long been the capital of the empire of Brazil. In contrast, the history behind São Paulo’s growth is much more associated with commercial reasons. For this reason, the lifestyle in São Paulo tends to be much more pragmatic than in Rio de Janeiro. This characteristic also influences the business model, as there are many more establishments in São Paulo that provide what people do not have time to do.0.1 Problem
We have two of the largest cities in the world with very distinct characteristics: São Paulo and Rio de Janeiro. Locally, each of these places acts like professional centers attracting professionals and companies. Despite the differences mentioned, it is expected that several specific neighborhoods of these cities have characteristics in common. One way to look for this similarity would be to consider the types of venues in each neighborhood. In this way, it would be possible to detect whether a neighborhood has characteristics more focused on commerce, leisure, sports, culture or housing. So, what we need here is a procedure capable of relating neighborhoods, not only from the same city, but also from different cities.
1.2 Interest
It is very common for people to have to move to another city. The reasons for this are quite diverse and can involve professional opportunities, personal reasons, among others. This process can be difficult for some people, as it involves adapting to a new and possibly different environment. Although two cities may be completely different, they may have neighborhoods with similar characteristics in common. Knowledge of this information can be crucial when choosing a new place to live in a new city. Thus, a person can choose to move to a neighborhood in a new city with similar characteristics to the neighborhood in the city where he lives in and is already acclimated.
Sometimes, a company in one of these cities is interested in a professional that lives in the other city. Certainly, if the professional finds a similar neighborhood, he will be more likely to accept an offer if it is professionally interesting.
2. Data
The name of all neighborhoods of São Paulo and Rio de Janeiro are needed to solve the problem. The data given at the site www.guiamais.com.br is used. The respective URLs are:
- (São Paulo): https://www.guiamais.com.br/bairros/sao-paulo-sp
- (Rio de Janeiro): https://www.guiamais.com.br/bairros/rio-de-janeiro-rj
We can see an example of data scraped from the pages in Fig. 01.

As the next step, we need to get the latitude and longitude of all neighborhoods. It can be done using the Nominatim search API, from OpenStreetMaps. An example of data with coordinates can be see on Figure Its possible to see the neighborhood positions in the maps of Figure 3.


The coordinated data are then used for the foursquare API in order to get the venue data of all neighborhoods. For this, I used the explore query:
https://api.foursquare.com/v2/venues/explore?&client_id={}&client_secret={}&v={}&ll={},{}&radius=5000&limit=1000
where the client_id, client_secret and v are credentials information, ll is the latitude and longitude of neighbors. I limited the search to up to 1000 venues within a 5 km radius of each neighborhood. We will need the name, categories and distance from neighborhood coordinates of each venue. An example of this data is given in Figure fig:04. This table is linked with the neighborhood table by the index nb_index. The radius of 5km may be to large for some neighbors. However, it is possible to select the best value of this parameter based on the quality of the clustering. This optimization procedure will be covered later.
3 Methodology
3.1 Pre-Processing
In this point, we have two main tables, which is that of Figures 2 and 4. We can merge this datasets by the nb_index. In fact, this is what will be done. However, it is convenient to allow the user to choose only the venues within a maximum radius determined by a parameter that we will call max_distance.
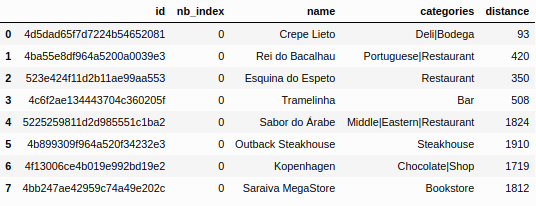
After this, we have to aggregate the venue table by nb_index and merge. At this point, we have a table with a column containing all the categories in a given neighborhood. These categories can be repeated within a row since the aggregation function concatenated the categories of all the neighborhood venues. An example of this table can be seen in the Fig. 5. The next step is count how many times each category appeared in total. The most common words are Shop appearing 8224 times, Gym with 6710, Place with 5573, Store with 5267 and Bar with 4352. I will consider only the words that appears more than a specified number of times. This number will be a new model parameter, called n_min, that I will optimize.

Selecting the most significant words, let’s count how many times each of these categories appears in each row. This value will be allocated in a new column with the category name. After this, the dataframe will look like the Fig. 5. After this, I will try two different types of interpretation. The first one is to scale the columns using the Min-Max approach. The second one is to consider every number greater then n_cats as 1 and 0 otherwise. The parameter n_cats is free and is something we have to find. We need the optimization procedure to determine which is the best. To proceed this pre processing step, I define a function called categories_processing that can be accessed in the GitHub Repository related to this project [1].
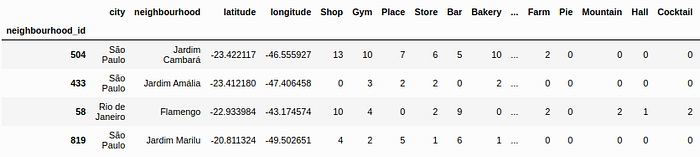
Figure 3: Example of count of categories in neighborhoods.
3.2 Model
The clustering procedure we choose is the KMeans [2]. We are not going to determine the number of clusters k and the algorithm now. These parameters will be kept free and optimized together with others in the same step.
3.3 Optimization
We have to determine the parameters max_distance, n_min, n_cats, k and algorithm before proceeding to the results. This will be done using a Markov-Chain-Monte-Carlo approach as a stochastic optimization procedure[3]. The metric to be used here will be the Calinski Harabasz score [4]. I will run a sample with 1000 iterations and get the optimal solution.
4 Results and Discussion
As commented before, the approach depends on parameters left free until now. To determine these parameters, I ran a MCMC sample with 1000 iterations and got the following optimized solution:
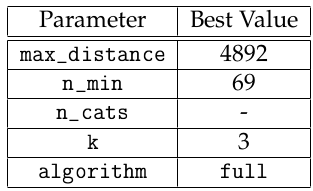
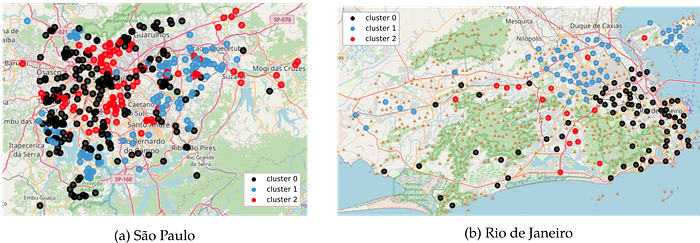
This parameters configuration means that we are considering that a venue is part of a neighborhood if it is within a radius of 4892 meters from its coordinates. The categories will be chosen if it appears at least 69 times through the venues. The optimization procedure select that the MinMax scaling approach is better than to consider every number greater then n_cats as 1 and 0 otherwise. So, n_cats is meaningless in this context. The optimal configuration for KMeans clustering is with 3 clusters, using the algorithm full. We can see the distribution of neighborhood with its respective labels in Fig. 7.
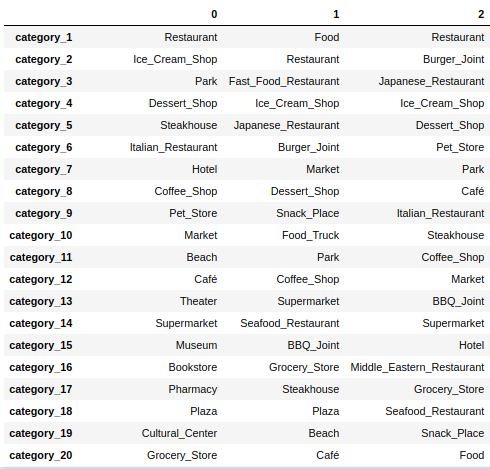
The most common words in each cluster can be seen in Fig. 8. We can see that a lot of words are appearing in all clusters. The reason for this is that both cities have a very strong urban profile. So, it is natural that venues that meet basic needs are recurrent. We can see that in cluster 0, we have categories as Beach, Park, Hotel Cultural Center and etc, showing us that this cluster is more associated with places with more leisure options. The cluster 1, we can see categories as Fast_Food_Restaurant, Burguer_Joint, Food_Truck and etc. This means that in these places people tend to look for places for fast food. This may be an indication that these are places aimed at professional or corporate environments.
5 Conclusion
It was possible to cluster the neighborhoods of both cities and determine three types of clusters. Maps showing the geographical distribution of these clusters have been generated, and indicate a relationship between the central regions of these cities, leisure regions and suburban regions.
References
[1] E. M. de Morais. GitHub Repository. Applied Data Science Capstone.
[2] J. MacQueen. Some methods for classification and analysis of multivariate observations. In Proceedings of the fifth Berkeley symposium on mathematical statistics and probability (Vol. 1, №14, pp. 281–297,1967).
[3] Andrieu, C., De Freitas, N., Doucet, A., & Jordan, M. I. (2003). An introduction to MCMC for machine learning. Machine learning, 50(1), 5–43.
[4] Caliński, T. and Harabasz, J. (1974). A dendrite method for cluster analysis, Communications in Statistics-theory and Methods 3(1): 1–27.
